Large Language Diffusion Model (LLaDA), Gemini Diffusion
Gemini Diffusion waitlist 를 받고 있다. waitlist 도 등록할 겸 Large Language Diffusion Models 논문도 함께 리뷰해본다.
- Paper: NIE, Shen, et al. Large language diffusion models. arXiv preprint arXiv:2502.09992, 2025.
- Gemini Diffusion: Gemini Diffusion - Google DeepMind
Large Language Diffusion Models (LLaDA) 을 처음 접한 것은 안될공학 유튜브였던 것 같다. 간단하게 설명하면 Image Diffusion 기술을 응용하여 언어 모델을 diffusion 방식으로 생성하는 아이디어이다.
당시 이미 상용화 수준으로 서비스를 하는 회사도 있었다. 그 후 불과 3개월만에 Google 에서도 diffusion 모델을 출시 한 것이다.
기술 산업은 정말 경쟁이 치열하다는 생각도 들고, 선다 피차이가 말했던 2등 전략이 어쩌면 이런 치열한 경쟁에서 살아남는 현명한 전략일지도 모른다는 생각이 든다.
Paper Review
What is now proved was once only imagined. —William Blake
재미있게도 논문은 위의 인용구로부터 시작된다.
기존에는 언어 모델이 단어를 생성하는데는 Auto-Regressive Modeling (ARM) 방법을 이용한다. 이는 이전까지의 생성된 출력을 다시 입력에 넣고 다음 단어를 만들어 내는 방식이다. 지금까지 많은 모델들이 이런 방식으로 동작하고 있다.
이런 방식에는 문제점이 있다. 한번에 처리할 수 있는 문장은 제한이 되어 있다. 따라서 출력해야 하는 문장이 길어질 경우 맨 처음 출력했던 단어를 비효율적으로 사용해야 하거나 문장길이의 제한으로 꼭 필요한 내용인데 입력으로 들어가지 못하는 경우가 생긴다.
저자는 이러한 ARM 의 단점을 보고, 다른 방법을 써도 괜찮은지 고민한 것 같다. Large language model 은 출력된 언어의 distribution 을 모델링 하는 것이기 때문에, distribution 을 잘 생성하는 검증된 방법인 diffusion 방법을 적용한다. LLM 의 여러 특성들은 언어모델 자체의 특성이며, ARM 이 수행하는 무손실 압축 특성은 다른 확률 모델로도 충분히 수행할 수 있다고 말한다.
Diffusion 방법은 은 노이즈로 부터 이미지를 생성하는 과정을 학습한다. 이를 통해 요청된 쿼리로부터 노이즈를 적당하게 생성하고 이로부터 다양하고 높은 퀄리티의 이미지를 만들어 내는 일을 수행한다. 그 과정은 diffusion 이라는 말이 의미 하듯이 노이즈를 점차 제거해 나가는 과정을 통해서 진행된다. (diffusion 의 forward 과정에서는 학습데이터이에 점차 노이즈를 확산시키며 학습할 데이터를 만들고 reverse 과정을 통해 노이즈로 부터 원래의 학습 데이터를 추정하는 방법을 배운다. 엄밀히 말하면 reverse diffusion 을 통해 노이즈를 제거한다.)
이미지 생성을 위해 사용되던 Diffusion 방법을 언어모델에 적용한 것이 LLaDA 이다.
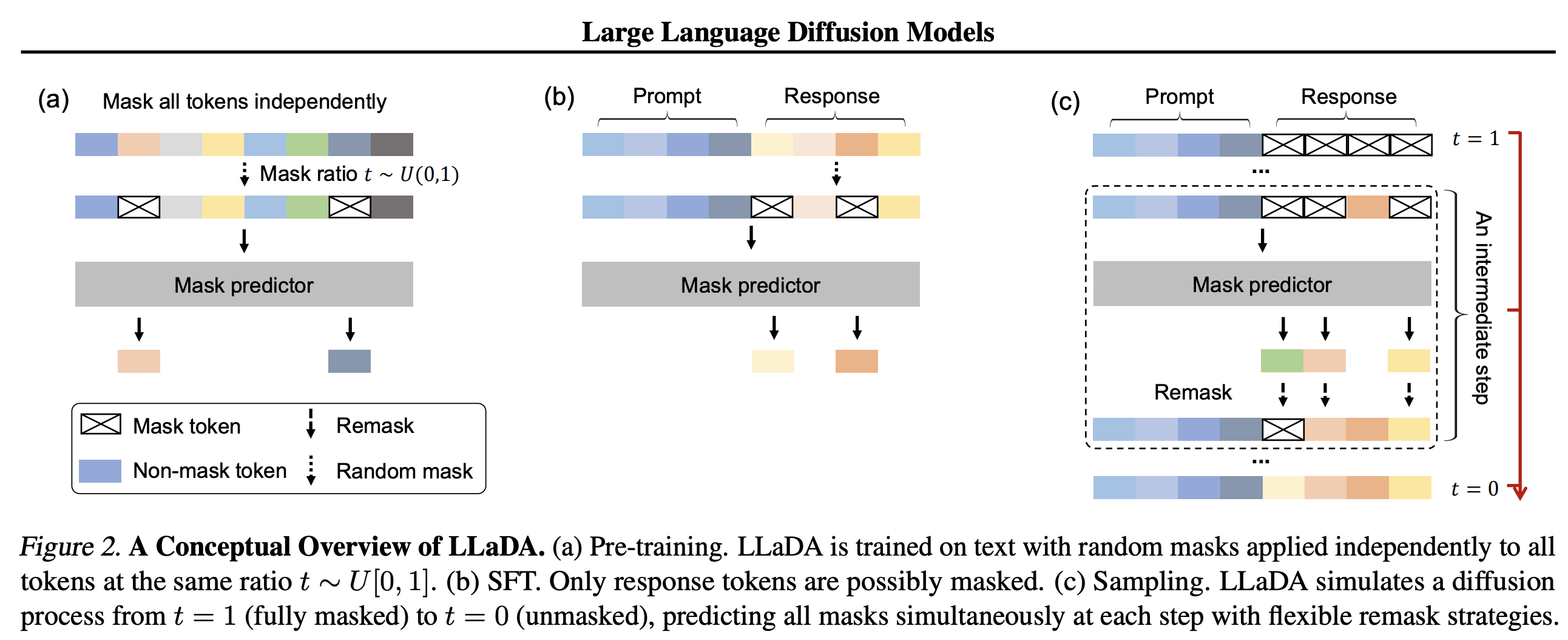
논문의 그림이 쉽게 잘 그려진 것 같다. (a) Pre-training 과정에서는 LLM 이 하듯이 많은 text 데이터에 masking 을 하고 이를 추론 하도록 학습을 한다. 기존의 LLM 과 동일한 방식이다. 이후에 (b) Supervised Fine-Tuning (SFT) 를 거쳐서 Prompt/Response 를 위한 mask predictor 를 학습 시킨다. 어쩌면 여기까지는 기존의 ARM 과 동일한 과정이라고 볼 수 있다. 큰 차이점은 LLaDA 는 (c) Inference 를 diffusion 과정을 통해서 수행 한다는 것이 큰 차이이다. (c) Inference 를 위해서 (a) Pre-training, (b) SFT 에서 diffusion 과정을 학습하게 된다.
Gemini Diffusion
Gemini Diffusion 은 이를 상용화 한 것으로 보인다.
Large Language Model, Image Diffusion, Large Language Diffusion 모두 이미 발표되었던 기술이어서 Google DeepMind 가 이를 어떤 수준으로 만들어서 상용화하는지 궁금하다.
기술적으로 보면 Diffusion 방법은 ARM 방법보다 획기적으로 빠른 방법이다.
한편으로 개인적으로는 드는 생각은 사용자 인터페이스 측면에서 ARM 방법은 LLM 이 생각을 하는 듯한 인상을 주기 때문에 좀 더 사람에게 친화적일 수 있을 것 같다. Demo 영상을 보면 Diffusion 모델은 그렇지는 않다. 상당히 기계적인 생성 과정으로 보인다. Diffusion 과정 자체가 사람들의 인지하기 좋은 방법은 아니기 때문이다.
아주 빠른 속도가 공학적으로는 더 좋은 결과일지도 모르지만 수년간 애플은 사용자의 심리적, 인지적 반응이 공학적으로 얼마나 중요한지 보여주었다. 대중이 어떻게 받아들일지가 궁금한 포인트이다.
Reasoning 을 통한 성능향상이 가능할지도 궁금하다. LLM 이 그랬던 것처럼 Diffusion 모델도 Reasoning 을 통해 성능 향상이 가능할지가 중요한 포인트 일 것 같다. 최근 OpenAI 에서 ChatGPT 의 새버전을 발표했는데 여러 벤치마크에서는 더 좋은 성능을 보여주었지만 환각 현상과 아부하는 현상이 심해서 버전을 roll-back 하는 초유의 사태도 있었다. 학습 과정에서 사용자 응답을 너무 많이 반영한 결과라고 하였지만 나는 개인적으로는 reasoning 과 같은 장치를 통해 이런 문제를 해결 할 것 같다는 생각이 든다.
발표한 모델의 사이즈도 꽤 작은 편인 것 같다. Diffusion 모델에도 Scaling-Law 가 적용되지 않을 수 도 있다는 가능성이 있어 보인다. Mamba, Jamba 같은 SSM 기반의 모델들이 아직 상용화에서는 많이 두각을 보이지 못하는 것을 보면 LLaDA 도 생각보다는 좀 더 시간이 필요할 수도 있어 보인다.