[Paper] Flash Attention Review
Overview
저는 현재 LLM 을 포함한 AI 모델, 그리고 이를 효율적으로 처리하기 위한 NPU/GPU 관련된 업무들을 다양하게 진행해 오고 있습니다. 이 글에서 리뷰하는 논문은 LLM 연산의 효율성을 크게 향상 시킨 FlashAttention 을 소개하는 논문입니다. 많은 뉴스에서 다뤄지고 있는 것처럼 현재 LLM 의 사용화를 위해 많은 업체들이 노력하고 있고, 그 중 가장 중요한 부분이 연산의 효율성 인 것 같습니다. 충분한 성능은 나오고 있고, 사용할 곳도 점점 많아지고 있으니 사용할때 드는 비용만 좀 더 낮아진다면 그만큼 더 큰 부가가치를 창출해 낼 수 있을 것이라 보는 것이죠.
FlashAttention 논문은 2022년에 발표되었고, 현재는 V2, V3 까지 나오면서 Transformer 기반의 LLM 모델의 효율성 향상에 큰 기여를 한 연구논문이다. Transformer 의 기반이 되는 Attention 레이어는 시퀀스 길이가 길어질수록 시퀀스길이의 제곱에 비례하는 연산량 증가로 인해 많은 연산시간과 메모리 사용량을 요구하게 된다. FlashAttention 은 이러한 문제를 해결하기 위해 GPU 메모리 사용을 효과적으로 개선할 수 있는 알고리즘을 제안하였고, 이를 통해 HBM 메모리 접근을 최소화 하면서 SRAM 을 적극적으로 사용하여 연산 속도를 향상시키는 결과를 보여주었다.
많이 알려진 것처럼 Transformer 의 성능은 메모리의 읽고쓰는 속도에 많은 영향을 받는다. 간단히 말하면 Transformer 에서 연산을 위해 필요한 데이터를 가져오거나 연산 결과를 메모리에 저장하는데 걸리는 시간이 데이터의 연산에 필요한 시간보다 많이 소요되기 때문이다. 이 연구는 이렇게 데이터를 가져오는 시간을 줄이기 위해 GPU 의 하드웨어적인 특성을 분석하고 좀 더 효율적으로 하드웨어를 활용하는 방법을 제안한다.
Introduction
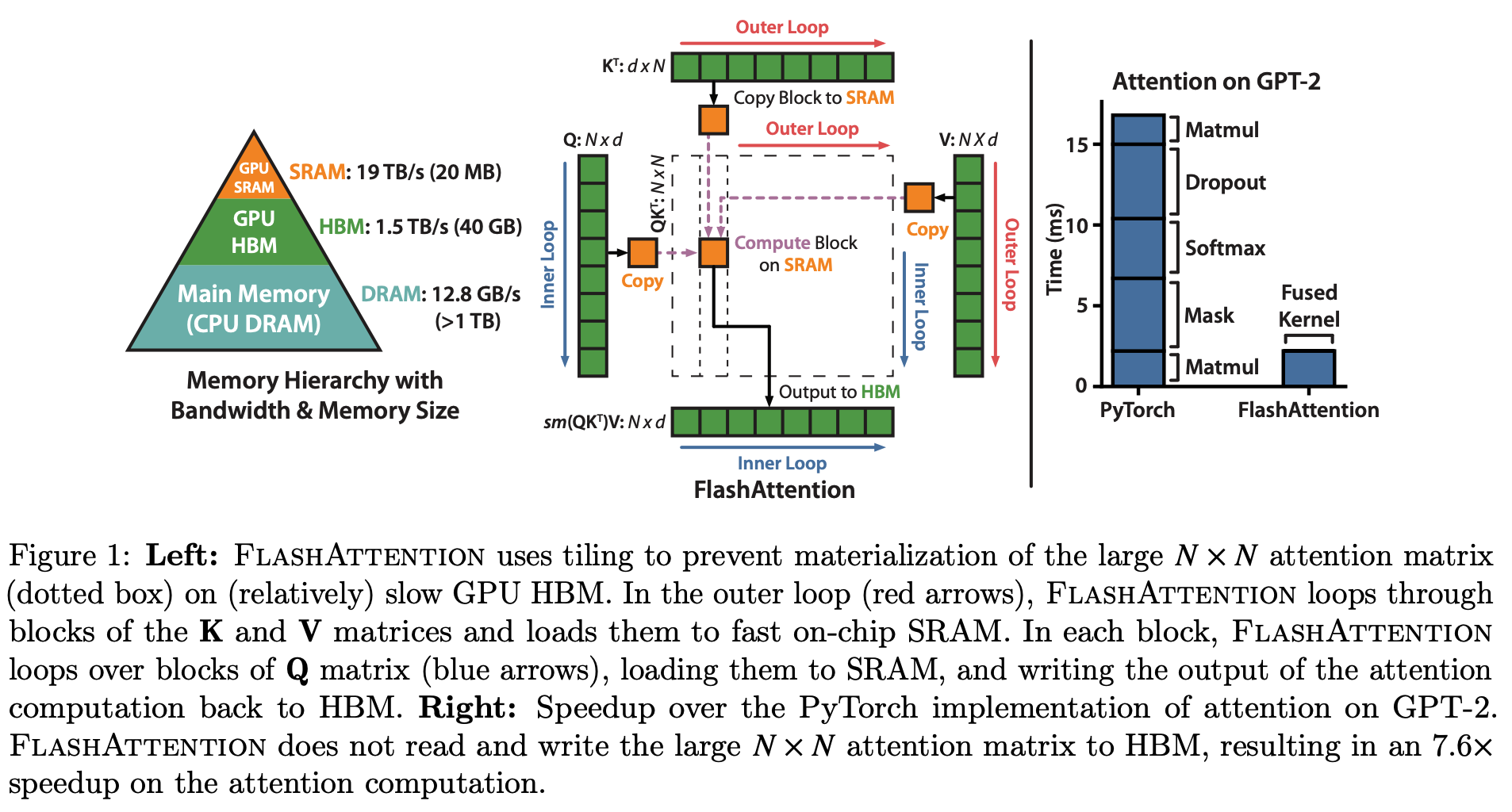
그림의 왼쪽 피라미드는 GPU 의 메모리 계층을 보여준다. Main Memory 의 데이터를 GPU HBM 으로 보내고, 이를 GPU SRAM 으로 일부 보내고 연산을 수행하고 다시 GPU HBM 에 보내는 방식으로 GPU 에서의 연산이 수행되게 된다. 이때 그림에서 나온 것처럼 각 계층의 메모리의 속도가 다르기 때문에 최대한 데이터의 이동을 줄이면서 속도가 빠른 메모리에서 더 많은 연산을 한다면 성능 개선이 가능해진다.
FlashAttention 은 이러한 하드웨어의 특성을 반영한다. 기존의 PyTorch 에서는 이를 지원하지 못한다.
Transformer 의 계산량을 줄이려는 노력은 다양한 방면으로 진행 되었다. sparsity 를 이용하거나 low-rank 를 기반으로한 근사 기법들은 연산량을 선형에 가깝게 감소시키긴 했지만, 기존 모델 대비 실제로 큰 속도 향상을 보여주지 못했다. 이러한 방법들은 연산의 수를 줄이긴 하지만, 메모리 접근에 대한 오버헤드를 줄여주지는 못했기 때문이다.
123123123
FlashAttention 은 GPU IO 계층을 효과적으로 사용하기 위해 타일링 (tiling) 방식을 적용하였고, 이는 결과적으로 HBM과 SRAM 사이의 메모리 read/write 숫자를 줄여주었다.
SRAM 사이즈에 따른 성능은?
Method
FlashAttention 의 목표는 attention matrix 를 HBM 으로 쓰거나 읽는 것을 피하는 것이다. 이를 위해 아마도 커널 코드를 개선한 것으로 보인다.