[SOTA] DSVT LiDAR 3D Object Detection
DSVT 모델은 MMDetection3D, OpenPCDet 등 다양한 open-source 로도 제공되고 있고, Transformer 를 이용하되, 별도의 custom operation 없이 구현하므로써 다른 모델에 비해 쉽게 배포가 가능하다는 장점이 있습니다. 이런 부분이 향후에 많은 어플리케이션에서 사용될 수 있는 여지가 많다고 생각하여 정리해 보았습니다.
Abstraction
- single-stride window-based voxel transformer backbone 제안
- dynamic sparse window attention → fully pallelization
- rotated set partitioning strategy → allow cross-set connection
- attention style 3D pooling → deploy friendly
Introduction
- Related Works
-
To efficiently process the attention on sparse data, many approaches rebalance the token number by random sampling [25,49]
[25] Pointformer CVPR2021 [49] Point transformer ICCV2021 -
group local regions with similar number of tokens together [10, 37]
[10] SST CVPR2022-
Attention token 생성을 위해 Bucketing 방법 사용
-
batch regions with similar number of tokens together and pads them separately to implement parallel computation.
[37] SWFormer ECCV2022
-
batch regions with similar number of tokens together and pads them separately to implement parallel computation.
-
-
[15, 24] try to solve these problems by writing customized CUDA operations
[15] Voxel Set Transformer CVPR2022-
customized CUDA for scatter function
[24] VoTr (Voxel Transformer) ICCV2021
-
proposes local attention and dilated attention with a self-designed voxel query to enable attention mechanism on sparse voxels
-
customized CUDA for query function
-
-
- Proposed methods
-
Dynamic sparse window attention → support efficient parallel computation
- 위와 같이 X 방향, Y 방향 두가지로 window 를 설정 함 (시험적으로 가장 좋은 성능을 보임, table 7 참조)
- X 방향 partition → self-attention → Y 방향 partition → self-attention 구조로 구성됨
- SST, SWFormer, SwinTransformer 보다 빠른 성능을 보여줌
-
Attention-style 3D pooling operation → downsmaple the feature map, generalization 능력 향상
- 기존 방법은 CUDA 코드 개발을 요구함, 제안한 방법은 CUDA 개발을 요구하지 않음?
- [11] FSD NIPS2022: custom CUDA kernel for scatter function
- [46] SECOND Sensors2018: custom CUDA kernel for downsampling features
- [50] VoxelNet CVPR2018: custom CUDA kernel for downsampling features
- 기존 방법은 CUDA 코드 개발을 요구함, 제안한 방법은 CUDA 개발을 요구하지 않음?
-
Methodology
-
Overview
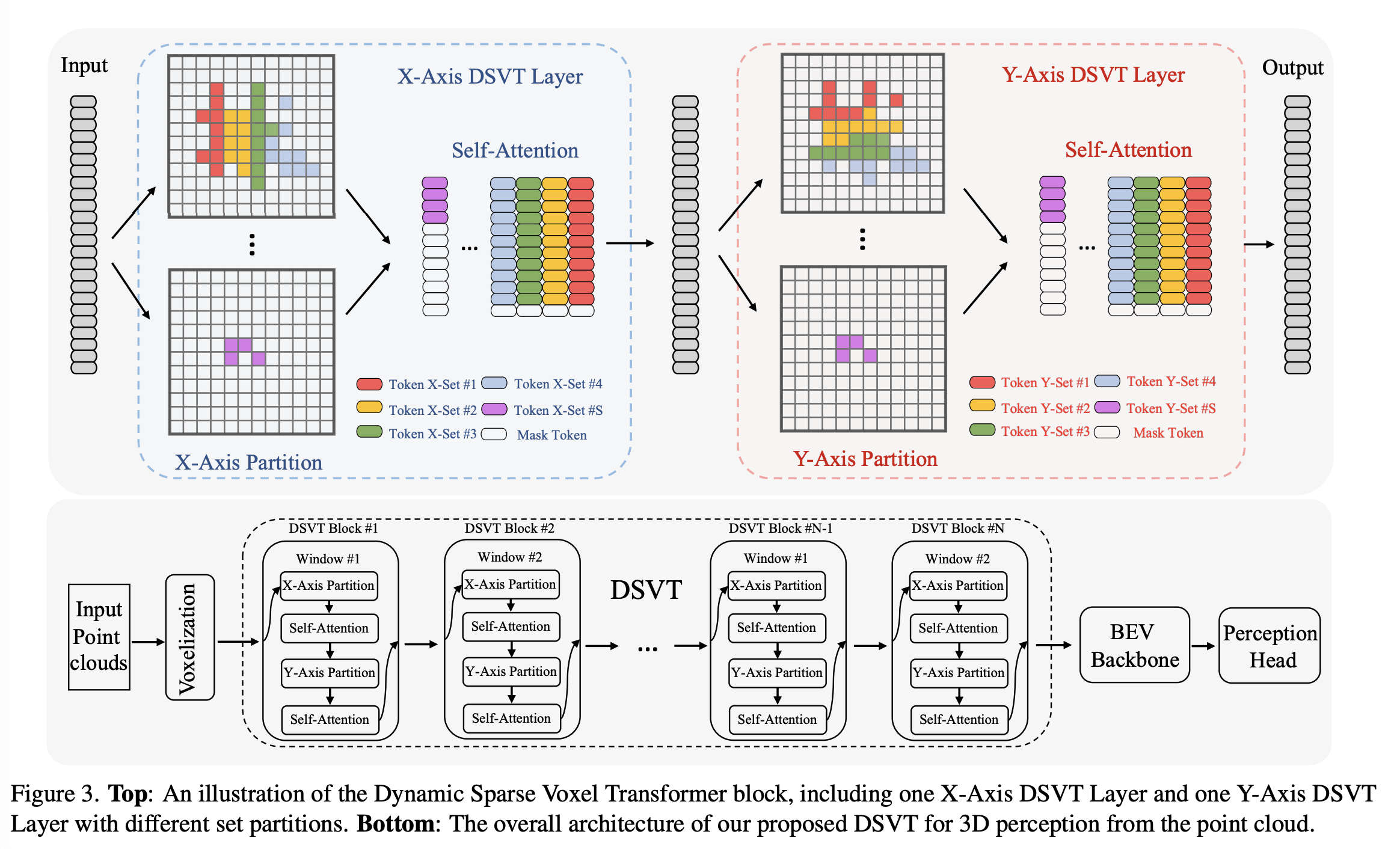
-
DSVT-P (pillar version, voxel 로 확장 가능)
-
Voxel Feature Encoding (VFE) 으로 sparse 한 voxel feature 를 얻음 → 각각의 voxel 들은 하나의 token 으로 처리함
[37] SWFormer ECCV2022 [45] PointPillars ECCV2020 [48] CenterPoint CVPR2021 -
SST 방식처럼 충분한 receptive field 를 얻고 작은 scale 의 object detection 을 수행하기 위해서 single stride network 적용 → X-axis, Y-axis 로 적용
-
-
Dynamic Sparse Window Attention
- Dynamic set partition
- window-bounded, size-equivalent subsets → enable parallel computations
- 3D Voxels 을 attention 을 위한 sub set 으로 나눈다
- voxel 마다 x, y 를 이용해 sorting 하고,
- x-axis partitioning, y-aixs partitioning을 수행한다.
- sub-set 은 voxel, coordinates 두가지로 구성되어 multi-head self-attention 으로 입력됨
- coordinates 은 positional encoding 적용
- Hybrid window partition for inter-window feature propagation.
- Swin-Transformer 도 적용
- Dynamic set partition
-
Attention-style 3D Pooling
