[SOTA] LiDAR 3D Object Detection Model: CenterFormer
최근 새로운 LiDAR 3D Object Detection Model 이 발표되었다. 기존의 CenterPoint 모델에 효과적으로 Transformer 구조를 적용한 CenterFormer 이다. Waymo 벤치마크에서 우수항 성능을 보여주며 3D Object Detection 분야에서 새로운 SOTA 모델이 되었다.
1. CenterPoint
CenterPoint는 효율적으로 center를 추출하고 이를 바탕으로 object detection 을 수행하는 네트워크이다. CenterNet이라는 이미지 object detection 네트워크의 아이디어를 포인트 클라우드 object detection 네트워크에 적용한 것이다.
CenterNet은 anchor-free 방식으로 heatmap 을 추출하고 heatmap의 peak 를 key-point로 사용하여 object detection 을 수행한다. CenterPoint역시 마찬가지로 포인트 클라우드로부터 heatmap 을 추출하고 이를 활용하여 object detection을 수행하는 구조를 제안하였다. 이때 VoxelNet 또는 PointPillars 모델과 같이 voxel 또는 pillar 형태로 encoding 및 feature들을 생성해 내고 이로부터 Bird-Eye-View (BEV) heatmap feature prediction을 수행하게 된다.
CenterNet의 경우 bounding box ground truth로 부터 Gaussian 분포로 encoding 된 heatmap 을 생성해 내어 이를 학습에 이용하였는데 CenterPoint도 동일한 방법을 사용하였다. Bounding box regression은 CenterPoint의 경우 object의 크기 위치 및 사이즈, 방향 등 3차원 object 정보를 추출해낸다.
2. Transformer
트랜스포머(Transformer)는 2017년 구글이 발표한 논문인 “Attention is all you need"에서 나온 모델로 기존의 seq2seq의 구조인 인코더-디코더를 따르면서도, 논문의 이름처럼 어텐션(Attention)만으로 구현한 모델이다. 이 모델은 RNN을 사용하지 않고, 인코더-디코더 구조를 설계하였음에도 번역 성능에서도 RNN보다 우수한 성능을 보여주었고, 최근에는 CNN이 수행하던 object detection 에도 적용되며 우수한 성능을 보여주고 있다.
3. CenterFormer
Overview
Transformer가 이미지 object detection에서 좋은 성능을 보이고 있지만, 상대적으로 포인트 클라우드 object detection에 Transformer를 적용하는 사례가 드물었다. CenterFormer는 포인트 클라우드에 Transformer를 적용하여 높은 성능을 달성했을 뿐만 아니라, 학습 속도를 향상시키고 네트워크의 크기를 줄일 수 있는 구조를 제안한다.
CenterFormer는 CenterPoint 와 마찬가지로 center feature 를 사용하며, 이러한 center feature들을 Transformer의 입력으로 사용된다. 또한 ‘multi-scale cross-attention layer’를 적용하여 neighboring features를 종합적으로 고려할 수 있게 하였는데, 즉 CNN과 같이 Convolution을 하는 것처럼 하나의 feature를 연산할때 그 주변의 feature들을 함께 연산하는 효과를 낸다고 볼 수 있다. 또한 이러한 aggregation 과정에서 큰 연산의 증가가 없어 효율적으로 모델 구성이 가능하다. 뿐만 아니라 CenterPoint와 같이 여러 프레임의 입력을 종합하기 위해 ‘cross-attention transformer’를 제안하여 CenterFormer에 적용하였다.
Detailed Method
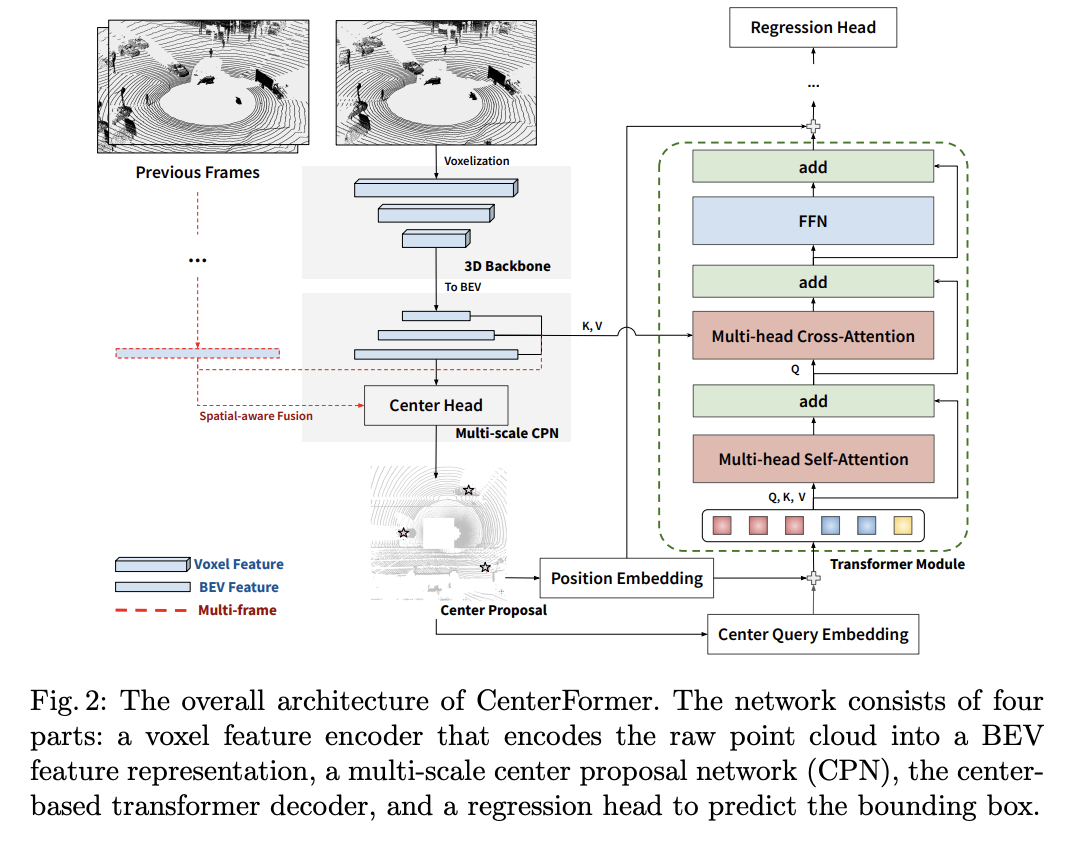
- 포인트 클라우드를 voxel 형태로 인코딩하여 사용하였으며, CenterPoint와 마찬가지로 sparse voxel-based backbone network 를 적용하였다. 이러한 네트워크를 통해 BEV features를 생성해낸다. CenterPoint의 경우 pillar 형태의 backbone 사용 결과도 나와있었지만 CenterFormer에는 해당 내용은 없었다.
- CenterPoint와 달리 multi-scale BEV features를 사용하여 center proposals를 prediction한다. 이를 Transformer의 decoder의 입력으로 사용하며, 마지막 regression head를 이용하여 object의 정보들을 prediction 하는 task를 수행한다.
Key Ideas
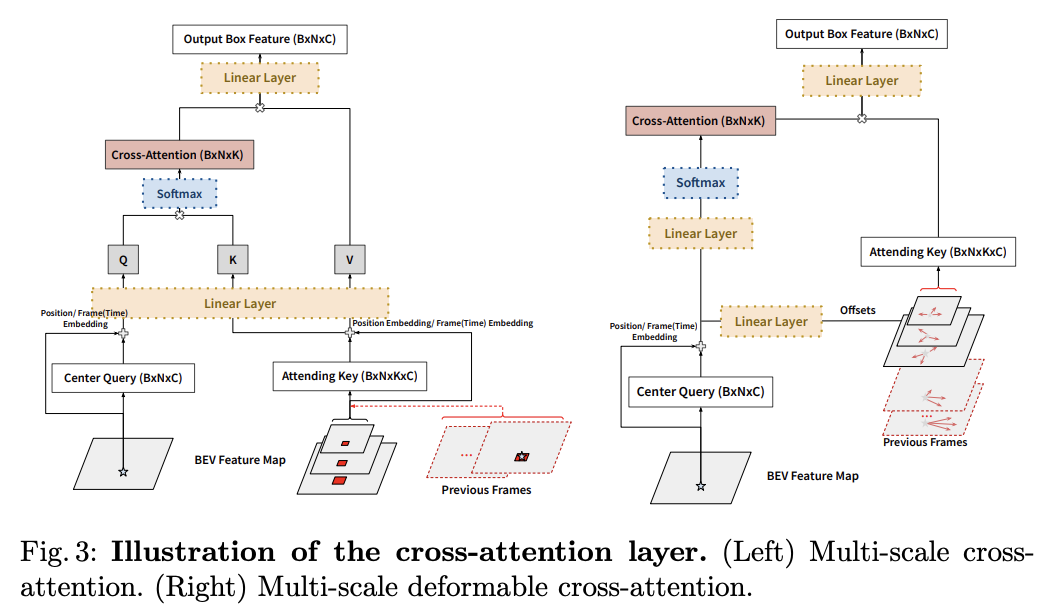
- Multi-scale Center Proposal Network
- DETR-style의 Transformer encoder는 feature bottleneck으로 fine-grained feature를 생성하는데 어려움이 있다고 한다. 이러한 문제를 해결하고자 feature pyramid network를 사용하고 여기에 Convolutional Block Attention Module (CBAM)을 적용하여 Transformer encoder를 대체하였다.
- Multi-scale Center Transformer Decoder
- Decoder의 경우 좀더 효율적인 연산을 위해 attending keypoints를 BEV전체에 적용하는 것이 아닌 center proposals 을 근처로 한 작은 크기의 window를 만들어 적용하였고 이를 통해 효율적인 Multi-scale cross-attention을 주행할 수 있게 하였다.
- Multi-scale Deformable Cross-attention Layer
- Deformable DETR에서 제안된 방법처럼 attending keypoints 를 sampling하여 학습에 적용하여 학습 결과가 좀 더 빠르게 수렴할 수 있도록 하였다.
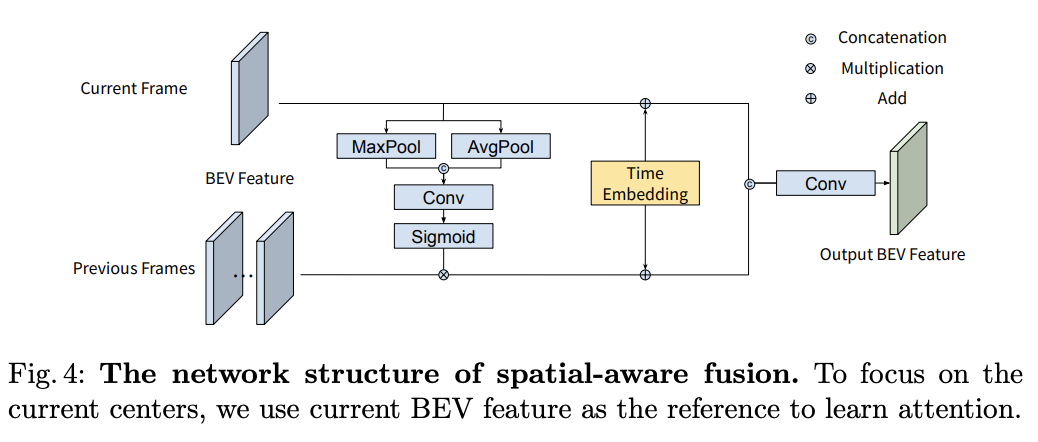
- Multi-frame CenterFormer
- Transformer의 장점은 attention 구조를 통해 과거의 데이터를 효과적으로 활용할 수 있다는 점이로 이러한 장점으로 인해 자연어 처리에 있어 우수한 성능을 낼 수 있었다.
- 이러한 장점을 활용할 수 있는 Multi-frame CenterFormer를 제안하였는데 BEV features와 CBAM 과 같은 attention 구조를 적용하여 효과적으로 과거의 frame들을 fusion할 수 있게 하였다.
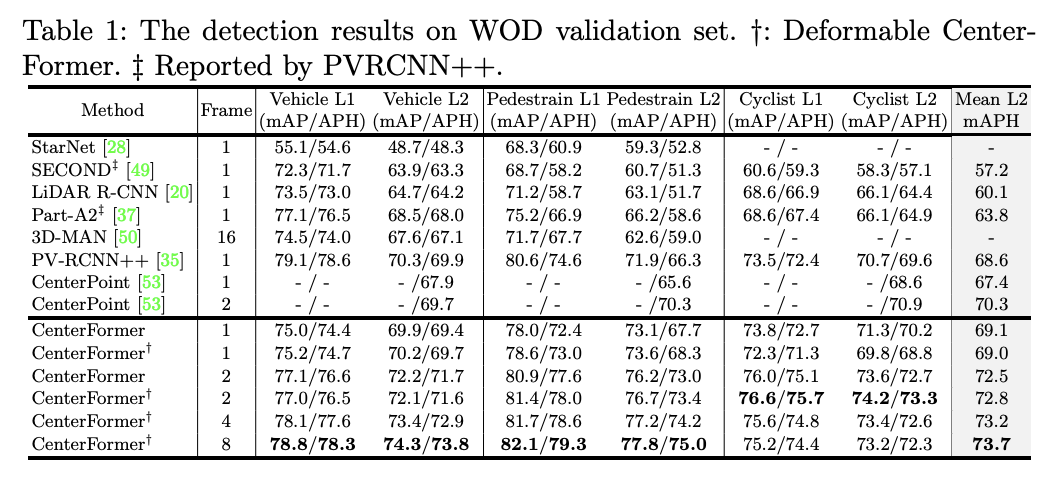
- 테스트 결과를 보면 fusion하는 frame이 많아질수록 정확도가 향상되는 것을 볼 수 있다.
On a Lighter Note…
저자를 보면 TuSimple 이라는 회사와 University of Centeral Florida 의 Computational Image Lab. 이 함께 연구한 모델인 것 같다. 저자의 LinkedIn을 보면 TuSimple 에서 인턴도 하는 등 두 회사와 연구실이 긴밀이 협업을 수행하는 것 같다.
실행 속도에 대한 결과가 없어 공식 Github를 찾아보니 single frame 에 80msec 정도 소요된다고 하니 실행속도도 그렇게 나쁘지 않은 것 같다. CenterPoint 모델의 경우 Python 모델의 경우 20FPS, TensorRT 모델의 경우 60FPS 까지 나온다고 하니 속도 착이가 크지 않아보인다. 그럼에도 불구하고 여러 벤치마크에서 우수한 성능을 보여주는 것으로 보아 Transformer를 적용한 3D object detection 도 향후 널리 이용될 것으로 보인다.
Reference
- CenterPoint
- Transformer
- CenterFormer